-
[MariaDB] ColumnStore Engine - Row-Oriented, Column-Oriented인프라/Database 2022. 3. 23. 23:39
들어가기 앞서
대량의 데이터를 저장해야하는 Database 는 보조기억장치에 저장됩니다.
CPU - 레지스터 - 캐시 - 메모리 - 보조기억장치
CPU가 명령어를 실행하고 연관된 데이터를 가져오려면 대략적으로 위와같은 단계로 가져옵니다.
가장빠른 레지스터와 가장 느린 보조기억장치 사이에는 엄청난 속도의 차이가 있고, CPU가 동작할 때는 네트워크도 마찬가지지만 가장느린 속도에 Sync를 맞추게 되어있습니다.
느린 보조기억장치에서 데이터를 얼마나 자주 가져오지 않느냐가 컴퓨터의 속도를 결정합니다.
그래서 용량은 적고 속도는 빠른 기억장치들에 데이터를 Cache 해놓고 CPU가 보조기억장치에 최소한으로 접근하도록 하는것이 관건입니다.
제가 경험해본 바로는 중복된 빅데이터의 집계를 낼 때 Row-Oriented 보다 Column-Oriented 의 테이블의 계산속도가 월등히 빨랐습니다. (대략 1000만건의 데이터를 기준으로 16초 -> 0.1초)
앞서 말한 내용을 기준으로 간단하게 말씀을 드리자면, 결국 CPU가 계산을 하기위해 값을 가져올 때 Row단위로 저장된 데이터 보다는 Column단위가 보조기억장치(하드디스크) 덜 접근하였다는 이야기입니다.
"덜 접근하였다" 이 말의 의미를 컴퓨터 입장에서 생각을 해보자면
"CPU가 데이터를 가져올 때 보조기억장치에 접근한 횟수가 적다" 는 의미일 것 같습니다.
메모리에 대해 공부를 하다보면 운영체제가 메모리에 올라가있는 프로세스를 실행할 때 Page라는 논리적인 단위로 메모리에 올리는 것을 알 수 있는데요.
32bit CPU의 경우 4KB의 블록단위로 메모리에 적재합니다.
Page(논리) -> Frame(물리) -> 없으면 가상메모리(보조기억장치)에 저장되어있는 Page
Page, Frame은 모두 같은 Size, 이후의 내용에선 이해하기 쉽도록 4KB로 설정보조기억장치에서 메모리로의 데이터 복사가 4KB단위로 적재
CPU가 프로그램 실행할 경우, 자주 접근하는 데이터가 메모리에 적재되는 단위인 4KB에 포함되어 있으면 빠를 것 입니다.
아주 간단하게 Row-Oriented, Column-Oriented를 그림으로 살펴보겠습니다.
CHAR(1024bytes)
CHAR(1024bytes)
CHAR(1024bytes)
CHAR(1024bytes)
Row당 4KB계산의 편의를 위해 각 1KB 컬럼 4개를 가지고 있는 테이블을 만들었습니다.
Row-Oriented
테이블에 4개의 Row가 삽입되어 있다고 가정해보겠습니다.

이 상황에서 4번째 컬럼에 있는 값들(a4, b4, c4, d4)을 가져오는 상황을 표현해보자면
0. 하드디스크에서 Page사이즈 4KB 만큼 메모리에 올린다.
① 1번째 Row 주소로 이동
② 4번째 컬럼은 3KB 뒤에 있으니 offset 3KB지점으로 이동 후 값을 얻습니다.
최종적으로 4개 Row 데이터의 4번째 컬럼들 만 가져오려고 4번 하드디스크에 접근하였습니다.
여기서 말하고자 하는 것은 Row-Oriented 기반의 테이블은 값을 가져오기위해서 Row로 이동 후 Column으로 이동 된다는 것입니다.
그럼 Column-Oriented를 살펴보겠습니다
Column-Oriented
a4, b4, c4, d4의 값이 하나의 블록(4KB)에 모여있기 때문에 1번의 메모리 적재 후 a4,b4,c4,d4를 전부 얻을 수 있었습니다.
간단한 예시를 통해서 한개 혹은 몇개의 컬럼만 가져오는 경우에는 Column-Oriented 테이블이 빠를 것으로 예상할 수 있습니다!
그럼 반대로 모든 컬럼을 가져오는 경우는 어떨까요?
Row-Oriented
a 데이터의 1,2,3,4 모두 가져오도록 하겠습니다.

Column-Oriented

한개 혹은몇개의 컬럼만 가져오는 경우랑은 정반대의 결과를 확인할 수 있습니다.
이와같이 Column-Oriented 테이블의 경우에는 대용량 데이터의 집계와 같은 소수의 Column에 접근하는 경에 사용하면 좋을 듯 합니다. 또한 Row에 저장, 수정, 삭제가 발생할 경우 분산되어있는 Column에 각각 접근해야하니 조회에 비해서는 많이 느립니다.
자주 변경되지 않는 대용량 데이터를 조회하는 테이블에 알맞는 형식인 듯 합니다.
또한 같은 데이터형식 모이다 보니 Column-Oriented의 경우 중복데이터에 매우 효율적입니다.

8개의 중복된 데이터가 있다고 가정하겠습니다.
여기서 4번째 컬럼값인 a4를 가져오기 위해서는
Row-Oriented의 경우

8번을 메모리에 적재하여 a4를 가져와야 합니다.
그러나 Column-Oriented의 경우

중복된 값들이 모여있기 때문에 압축하여 데이터를 저장할 수 있습니다.

이렇게 압축하여 저장하게되면
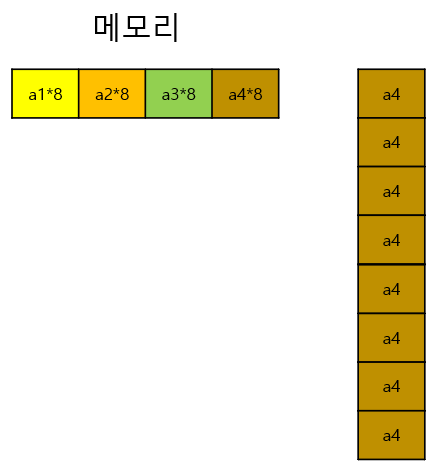
1번의 메모리 적재로 값을 얻을 수 있습니다.
정말 간단하게 제 나름대로 조사한 내용을 그림과 함께 설명드렸습니다만 이해가 되셨을지 모르겠습니다.
MariaDB ColumnStore Architecture를 링크하면서 이만 마치도록 하겠습니다.
- https://mariadb.com/kb/en/columnstore-storage-architecture/
ColumnStore Storage Architecture
MariaDB ColumnStore Storage Architecture and Concepts
mariadb.com
참고
- https://en.wikipedia.org/wiki/Column-oriented_DBMS
- https://nesoy.github.io/articles/2019-10/Column-Oriented-DBMS
- https://dataschool.com/data-modeling-101/row-vs-column-oriented-databases/
- https://www.secmem.org/blog/2021/02/21/lsm-tree/
- http://www.secmem.org/blog/2019/05/17/bloom-filter/
- https://www.youtube.com/watch?v=aZjYr87r1b8
- https://people.brandeis.edu/~nga/papers/VLDB05.pdf
'인프라 > Database' 카테고리의 다른 글
[MariaDB] ColumnStore Engine 회고 (0) 2022.03.13
